日元技术分析:美元/日元迈向145关键点位
2023-07-19 16:03
日元亮点:
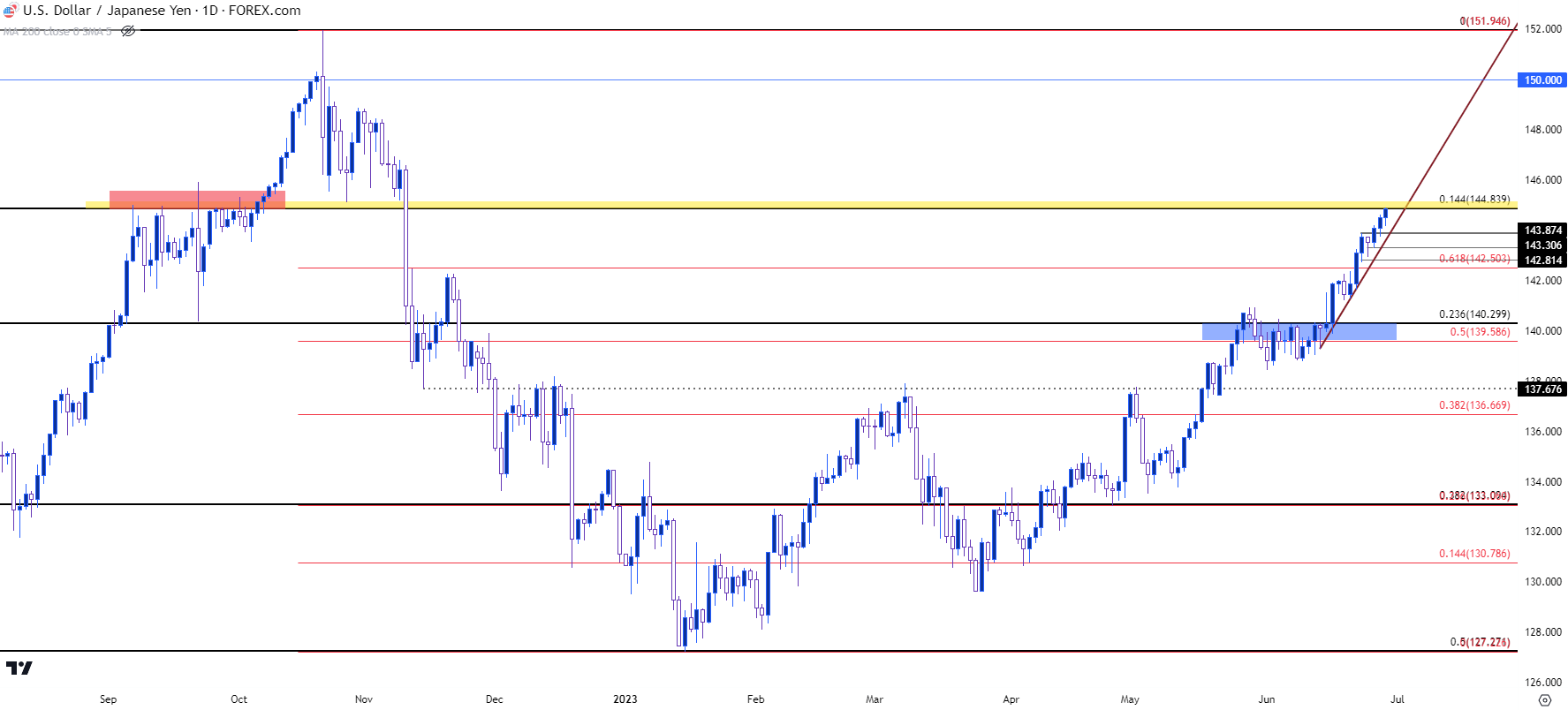
- 日元疲软继续助推美元,该货币对现在接近145的关键点位,这是去年上涨期间的重要点位,多头最终测试150之前在此处停滞了大约一个月。150是财务省主动干预的点位,帮助该货币对去年在此封顶。
- 迄今为止,即使通胀率保持在2%以上,日本央行的货币政策也没有改变的迹象。随着焦点转向美联储的进一步加息,套利交易继续推动该货币对的看涨趋势。
- 我将在美国东部时间周二下午1点的每周网络研讨会上深入讨论这些主题。所有人都可以免费注册:单击此处进行注册。
套利交易一直伴随着美元/日元再次创下2023年新高并且逼近图表上的关键点位,该点位在去年的价格走势中发挥了重要作用。
去年,由于日本央行保持被动和鸽派政策,同时美联储急于加息,套利交易全面开花。这使得美元/日元以激进的上行趋势从3月份的低于115升至9月份的145。一个主要货币对发生3,000点的变化会对经济基础产生影响;随着价格上升到145,人们开始猜测日本财务省可能会介入此事。
去年触及145时没有发生这种情况,但不久之后确实发生了。不过,阻力位145使上涨停滞了大约一个月,即从去年9月7日到10月6日,随后价格终于在日线图上形成了对该点位的突破。不久之后,美元/日元跃升至下一个主要心理点位150,这最终引发了干预,在10月份飙升至150关口上方后,财务省命令日本央行通过买入日元进行干预。
那么现在价格又回到了145关口;准确地说是几乎,因为今天的高点目前录得144.90。
美元/日元日线图
图表由James Stanley绘制,TradingView上的美元/日元
美元/日元:过往记录
去年145令走势停滞,对干预的猜测或恐惧使多头观望了一个月,最终财务省下令在150的点位出手干预。
同样的情形会在相同的点位上演吗?目前还无从知晓,但财务省已经放出了消息。就在几天前,铃木俊一表示,美元/日元最近形成了“迅速的单边走势”,他们通常会在关注此事时发表这样的评论。铃木表示,如果趋势持续且过度,政府将“采取适当的回应”。
虽然这并不一定意味着多头即将面临厄运,但它确实突显了这轮走势的理论上限就在日本可能采取某种干预的点位。按道理讲,交易者可能会参考过去的记录,从而判断从何处开始树立这些预期。
多头的风险看来会是关于未来干预的相关言论,正如我们本周早些时候听到的消息。美元/日元的趋势仍然强劲,多头继续推动单边走势,最近只有略微的回调。到目前为止,这些干预的言论只能带来短期回调,但正如我们去年看到的那样,当财务省下令干预时,反应可能会很大巨大。
美元/日元的涨势花了21个月的时间才达到去年10月的高点;但仅用了三个月就抹去了50%,最终在2021-2022年重大走势的50%支撑位企稳。
美元/日元周线图

图表由James Stanley绘制,TradingView上的美元/日元
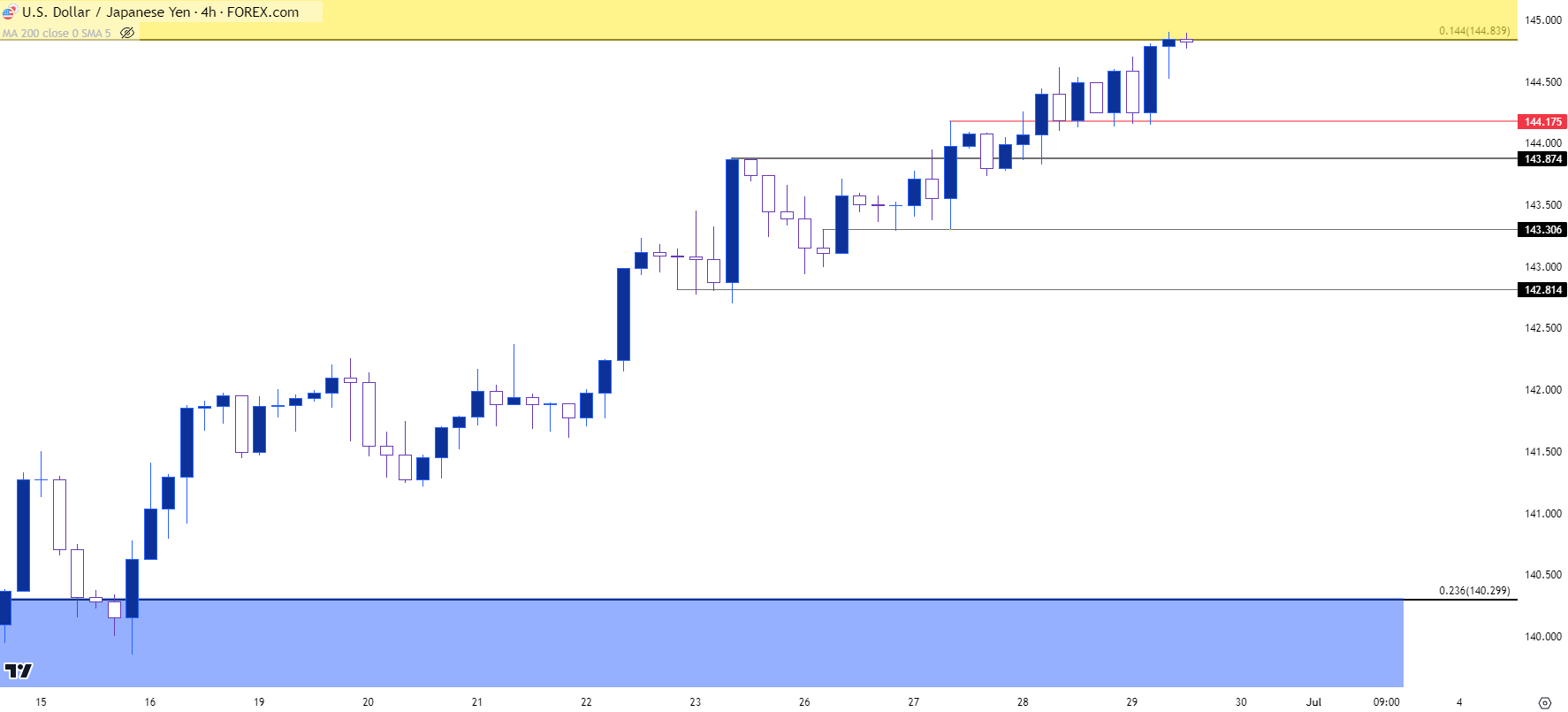
美元/日元短期
目前美元/日元面临的挑战是单边趋势,因为最近回调幅度很小。随着价格现在重新测试之前表现出阻力的区域,涨势潜力的问题仍然存在,特别是考虑到财务省大臣的言论会引发抛售的可能性。
但令人纠结的是,这看来是目前对多头最有吸引力的机会;即来自财务省大臣的言论引起了该货币对的回调。如果在回调后有支撑位,没有明显的实际干预迹象,那么可能仍有上行潜力。但应谨慎行事,因为干预本身或干预风险可能会给市场参与者、政府和央行行长带来许多未知的变量。
在下面的四小时图上,我总结了最近的一些看涨结构,以及一些潜在的支撑位。
美元/日元四小时图
图表由James Stanley绘制,TradingView上的美元/日元
相关资讯

2023-08-01 17:15:58
英镑/美元展望:英国CPI走弱后引发对前阻力位的测试
英镑展望:英镑/美元 在英国CPI降幅远超预期后,英镑/美元继续承压,收于6月高点(1.2848)附近的前阻力区下方可能会导致汇率大幅下跌,同时相对强弱指数(RSI)继续从超买区域回落。 英镑/美元展...

2023-08-01 17:15:40
美元价位行情:欧元/美元、美元/日元
美元亮点: 上周美元卷土重来,但随着本周后半段美国将有两个影响极大的事件——周三是FOMC利率决议,周五是美联储首选通胀指标核心PCE发布,让我们拭目以待。 两周前,美元在美国CPI数据发布后下跌。随...

2023-07-19 16:12:37
欧元短期展望:欧元/美元紧盯上行阻力斜线
欧元技术展望:欧元/美元短期交易点位 欧元较5月低点飙升逾3.1% 欧元/美元突破6月开盘区间,正在测试第一个重大阻力关口 阻力位~1.0955/80、1.1041、1.1075/95(关键)-支撑位...

2023-07-19 16:11:30
欧元价格展望:欧元/美元重新测试1.1000阻力位
欧元亮点: 欧元/美元延续了上周以来的涨势,今天早些时候在1.1000关口处遇阻,该点位迄今为止一直力保高点不失。 1.1000-1.1100的阻力区域今年多次发挥作用,在2月和4月帮助守住高点。下面...

2023-07-19 16:08:56
美元技术预测:欧元/美元、英镑/美元、美元/日元
美元亮点: 美元本周重新测试了DXY上的102,该点位守住了DXY的低点,同时带来反弹,令价格重新测试103阻力位。 下周焦点将转移到通胀上,周五将公布美联储看重的通胀指标核心PCE。其他驱动美元的因...

2023-07-19 16:07:23
欧元价格展望:欧元/美元分界线
欧元亮点: 欧元/美元继续6月涨势,上周重新测试1.1000关口。 在欧洲PMI数据公布后,周五早盘出现大幅回调,但截至目前,欧元/美元在1.0843附近一直有支撑。 随着我们2023年即将过半,欧元...